Hosting a Keyword Extraction Model with Flask and FastAPI

Introduction
When you noticed learning how to build a machine learning model is not enough, you are graduating from the Data Science bootcamp.
Here is an introduction of ML model serving with Restful API endpoint.
Overview
In this post, we will be covering the following topics
- Yet Another Keyword Extractor
- Our ML model
- Flask API
- Testing with curl
- FastAPI
- Testing with Postman
At the end of this post, we will have an API endpoint (from localhost) to extract 20 keywords from a text paragraph with a simple POST requests.
Yet Another Keyword Extractor
YAKE (Yet Another Keyword Extractor) is a light-weight unsupervised automatic keyword extraction method. It rests on text statistical features extracted from single document to select the most important keywords.
It is quite useful to extract details from a text paragraph or use it as an alternatives to labeled data (When you don’t have any).
Main Features
- Unsupervised approach
- Single-Document
- Corpus-Independent
- Domain and Language Independent
Heuristic Approach
As opposed to other keyword extraction algorithms like tf-idf, one of the strong selling points of YAKE is its ability to extract keywords within a single document. It can be easily applied to single paragraph or document, without the existence of a corpus, dictionary or other external collections.
Here are some components of the method outlined in the paper.
- Text preprocessing
- Feature extraction
- Individual terms score
- Candidate keywords list generation
- Data deduplication
- Ranking
Some interesting ideas during the term scoring process.
-
Casing
Reflects the casing aspect of a word.
-
Word Positions
Values more on the words occurring at the beginning of the documents, on the assumption that relevant keywords often concentrate more at the beginning.
-
Word Relatedness to Context
Computes the number of different terms that occur to the left and right side of the candidate word. The more the number of different terms co-occur with the candidate word (on both sides), the more the meaningness it is likely to be. Similar idea applies to different sentences as well.
For more details, you can check out the paper in the reference page.
Our ML model
As the main purpose of this post is to demonstrate how to deploy a model with API endpoints, I will use a simple wrapper of yake.KeywordExtrator function to act as our machine learning model.
Installation
pip install yake
Our model
import yake
def ExtractKeywords(text):
""" Extract 20 keywords from the input text """
language = "en"
max_ngram_size = 2
deduplication_thresold = 0.3
deduplication_algo = "seqm"
window_size = 1
num_of_keywords = 20
custom_kw_extractor = yake.KeywordExtractor(
lan=language,
n=max_ngram_size,
dedupLim=deduplication_thresold,
dedupFunc=deduplication_algo,
windowsSize=window_size,
top=num_of_keywords,
features=None,
)
kws = custom_kw_extractor.extract_keywords(text)
keywords = [x[0] for x in kws] # kws is in tuple format, extract the text part
return keywords
Flask API
Having a ML model ready is only half the job done. A model is useful only when someone is able to use it.
Now we are going to serve our model with a Restful API endpoint using Flask. The package uses a simple decorator format for you to define an endpoint, e.g. @app.route('/keywords', methods = ['POST', 'GET']).
Here we specify our endpoint to accept both GET and POST requests. The GET request will print a curl statement, and the POST request will extract the keywords.
Installation
pip install flask
Serve with /keywords endpoint
from flask import Flask, request
import yake
app = Flask(__name__)
def ExtractKeywords(text):
""" Extract 20 keywords from the input text """
language = "en"
max_ngram_size = 2
deduplication_thresold = 0.3
deduplication_algo = "seqm"
window_size = 1
num_of_keywords = 20
custom_kw_extractor = yake.KeywordExtractor(
lan=language,
n=max_ngram_size,
dedupLim=deduplication_thresold,
dedupFunc=deduplication_algo,
windowsSize=window_size,
top=num_of_keywords,
features=None,
)
kws = custom_kw_extractor.extract_keywords(text)
keywords = [x[0] for x in kws] # kws is in tuple format, extract the text part
return keywords
@app.route('/keywords', methods = ['POST', 'GET'])
def keywords():
if request.method == "POST":
json_data = request.json
text = json_data["text"]
kws = ExtractKeywords(text)
# return a dictionary
response = {"keyowrds": kws}
return response
elif request.method == "GET":
response = """
Extract 20 keywords from a long text. Try with curl command. <br/><br/><br/>
curl -X POST http://127.0.0.1:5001/keywords -H 'Content-Type: application/json' \
-d '{"text": "Logistic regression is a statistical model that in its basic form uses a logistic function to model a binary dependent variable, although many more complex extensions exist. In regression analysis, logistic regression[1] (or logit regression) is estimating the parameters of a logistic model (a form of binary regression). Mathematically, a binary logistic model has a dependent variable with two possible values, such as pass/fail which is represented by an indicator variable, where the two values are labeled 0 and 1. In the logistic model, the log-odds (the logarithm of the odds) for the value labeled 1 is a linear combination of one or more independent variables (predictors); the independent variables can each be a binary variable (two classes, coded by an indicator variable) or a continuous variable (any real value). The corresponding probability of the value labeled 1 can vary between 0 (certainly the value 0) and 1 (certainly the value 1), hence the labeling; the function that converts log-odds to probability is the logistic function, hence the name. The unit of measurement for the log-odds scale is called a logit, from logistic unit, hence the alternative names. Analogous models with a different sigmoid function instead of the logistic function can also be used, such as the probit model; the defining characteristic of the logistic model is that increasing one of the independent variables multiplicatively scales the odds of the given outcome at a constant rate, with each independent variable having its own parameter; for a binary dependent variable this generalizes the odds ratio."}'
"""
return response
else:
return "Not supported"
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5001, debug=True)
Host the server with port 5001 app.run(host="0.0.0.0", port=5001, debug=True)
python main.py
Reference - Flask
Testing with curl
Let’s use a paragraph from wikipedia of the Logistic Regression page as an input of our curl command and pass it as an argument text (Double quote removed) to the model.
curl -X POST http://127.0.0.1:5001/keywords -H 'Content-Type: application/json' \
-d '{"text": "Logistic regression is a statistical model that in its basic form uses a logistic function to model a binary dependent variable, although many more complex extensions exist. In regression analysis, logistic regression[1] (or logit regression) is estimating the parameters of a logistic model (a form of binary regression). Mathematically, a binary logistic model has a dependent variable with two possible values, such as pass/fail which is represented by an indicator variable, where the two values are labeled 0 and 1. In the logistic model, the log-odds (the logarithm of the odds) for the value labeled 1 is a linear combination of one or more independent variables (predictors); the independent variables can each be a binary variable (two classes, coded by an indicator variable) or a continuous variable (any real value). The corresponding probability of the value labeled 1 can vary between 0 (certainly the value 0) and 1 (certainly the value 1), hence the labeling; the function that converts log-odds to probability is the logistic function, hence the name. The unit of measurement for the log-odds scale is called a logit, from logistic unit, hence the alternative names. Analogous models with a different sigmoid function instead of the logistic function can also be used, such as the probit model; the defining characteristic of the logistic model is that increasing one of the independent variables multiplicatively scales the odds of the given outcome at a constant rate, with each independent variable having its own parameter; for a binary dependent variable this generalizes the odds ratio."}'
Demo

Results
{
"keywords": [
"logistic model",
"variable",
"regression",
"binary dependent",
"labeled",
"form",
"odds",
"exist",
"basic",
"complex",
"indicator",
"probability",
"log-odds scale",
"sigmoid function",
"converts log-odds",
"Mathematically",
"scales",
"alternative",
"defining",
"constant"
]
}
The result is actually quite good given its unsupervised nature. We can see some important keywords like log-odds, sigmoid function and binary in the result.
FastAPI
Apart from Flask that we just introduced, there is another popular package to host API endpoints - FastAPI.
FastAPI is a modern, fast and popular web framework for building APIs based on standard Python type hints. It is a high performant package, and it is on par with some popular framework written in NodeJS and Go.
Let’s try to host our keywords model again with FastAPI.
Key steps
- Both Input and Output Object inherit
pydantic.Basemodelobject - Use python type hints
str(input) andList[str](output) to define field types of the objects - Use Objects as input/output parameter
Response/Paragraph
# Input object with a text field
class Paragraph(BaseModel):
text: str
# Output object with keywords as field
class Response(BaseModel):
keywords: List[str]
@app.post("/keywords", response_model=Response)
def keywords_two(p: Paragraph):
...
return Response(keywords=kw)
Code
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List
import yake
# Input
class Paragraph(BaseModel):
text: str
# Output
class Response(BaseModel):
keywords: List[str]
app = FastAPI()
def ExtractKeywords(text):
""" Extract 20 keywords from the input text """
language = "en"
max_ngram_size = 2
deduplication_thresold = 0.3
deduplication_algo = "seqm"
windowSize = 1
numOfKeywords = 20
custom_kw_extractor = yake.KeywordExtractor(
lan=language,
n=max_ngram_size,
dedupLim=deduplication_thresold,
dedupFunc=deduplication_algo,
windowsSize=windowSize,
top=numOfKeywords,
features=None,
)
kws = custom_kw_extractor.extract_keywords(text)
keywords = [x[0] for x in kws] # kws is in tuple format, extract the text part
return keywords
@app.post("/keywords", response_model=Response)
def keywords(p: Paragraph):
kw = ExtractKeywords(p.text)
return Response(keywords=kw)
Host
a) Install fastapi and uvicorn
pip install fastapi
pip install uvicorn
b) Host FastAPI with uvicorn
uvicorn main:app --host 0.0.0.0 --port 5001 --reload --debug --workers 3
Documentation
FastAPI creates a documentation page for you by default using the Swagger UI. You can open the documentation page with http://localhost:5001/docs. If you follow the schema definition, you can have a nice looking API documentation with some examples as well.
Figure 1: Auto generated Swagger API doc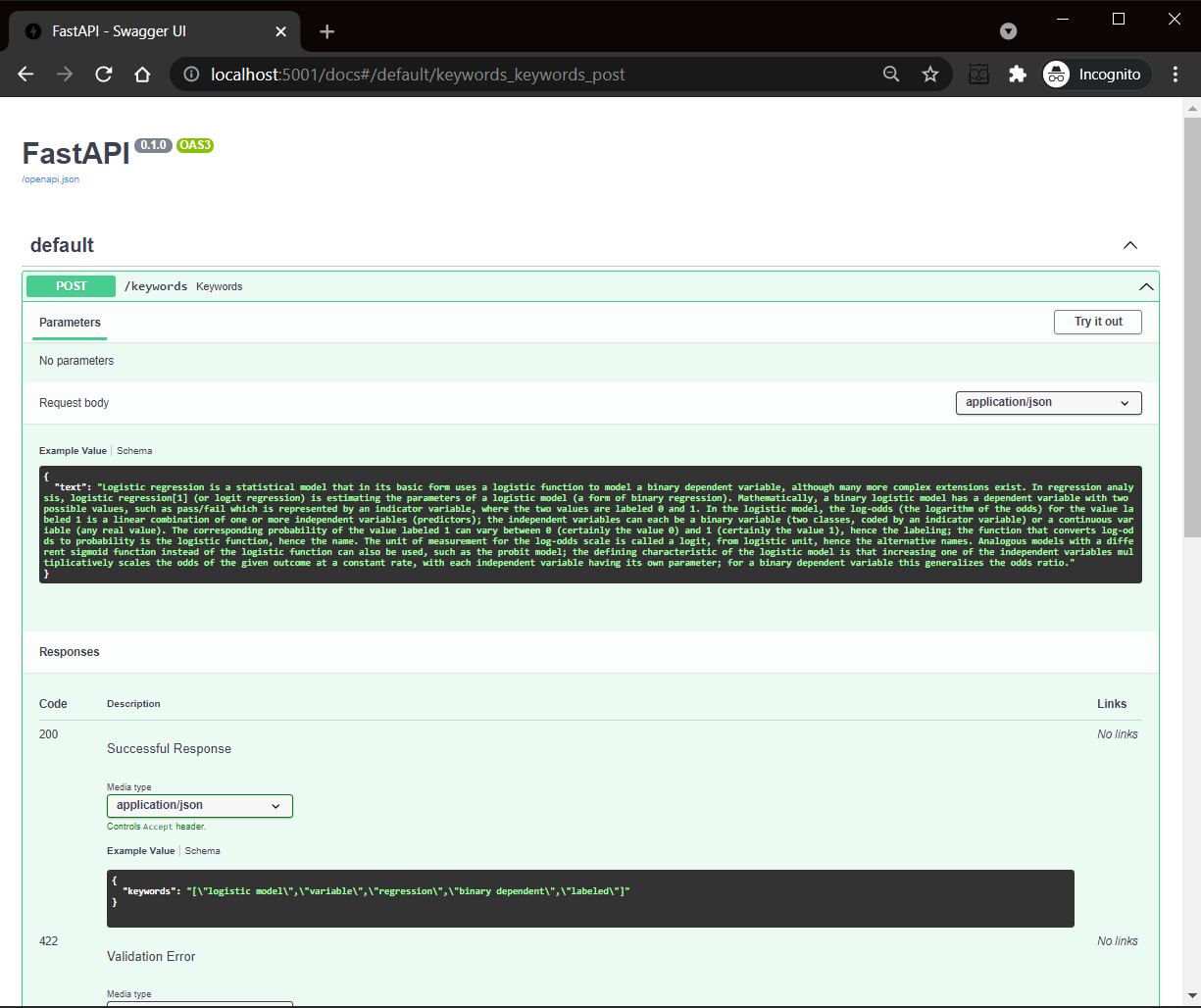
Reference - FastAPI and Declare Request Example
Testing with Postman
Demo

Complete example
You can find the complete examples here - Flask and FastAPI
Final thoughts
Here we introduced two different frameworks (Flask and FastAPI) to serve our keyword extraction model on our local machine. While Flask being more popular among web developers, and FastAPI being more performant, it is both pretty easy to use.
Hopefully you can see how easy it is for you to host the model using the frameworks. If you have any questions or feedback, feel free to leave a comment.
Happy Coding!
Recommended Readings


Reference: